前言
欢迎来到菜鸟SpringCloud实战入门系列(SpringCloudForNoob),该系列通过层层递进的实战视角,来一步步学习和理解SpringCloud。
本系列适合有一定Java以及SpringBoot基础的同学阅读。
每篇文章末尾都附有本文对应的Github源代码,方便同学调试。
Github仓库地址:
https://github.com/qqxx6661/springcloud_for_noob
菜鸟SpringCloud实战入门系列
你可以通过以下两种途径查看菜鸟SpringCloud实战入门系列:
- 关注我的公众号:Rude3Knife 点击公众号下方:技术推文——SpringCloud
- 菜鸟SpringCloud实战入门专栏导航页(CSDN)
前文回顾:
- [菜鸟SpringCloud实战入门]第一章:构建多模块的Maven项目+创建注册中心Eureka子模块
- [菜鸟SpringCloud实战入门]第二章:创建服务提供者并在Eureka进行注册
- [菜鸟SpringCloud实战入门]第三章:将Eureka改造为高可用集群
- [菜鸟SpringCloud实战入门]第四章:远程调用服务实战
- [菜鸟SpringCloud实战入门]第五章:熔断器Hystrix的使用 + 可视化监控Hystrix Dashboard和Turbine
- [菜鸟SpringCloud实战入门]第六章:配置中心Spring Cloud Config初体验
- [菜鸟SpringCloud实战入门]第七章:配置中心客户端主动刷新机制 + 配置中心服务化和高可用改造
- [菜鸟SpringCloud实战入门]第八章:通过消息总线Spring Cloud Bus实现配置文件刷新(使用Kafka)
- [菜鸟SpringCloud实战入门]第九章:服务网关Zuul体验
实战版本
- SpringBoot:2.0.3.RELEASE
- SpringCloud:Finchley.RELEASE
—–正文开始—–
分布式链路跟踪 Sleuth和Zipkin
分布式链路跟踪介绍
对于一个微服务系统,大多数来自外部的请求都会经过数个服务的互相调用,得到返回的结果,一旦结果回复较慢或者返回了不可用,我们就需要确定是哪个微服务出了问题。于是就有了分布式系统调用跟踪的诞生。
现今业界分布式服务跟踪的理论基础主要来自于 Google 的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,使用最为广泛的开源实现是 Twitter 的 Zipkin,为了实现平台无关、厂商无关的分布式服务跟踪,CNCF 发布了布式服务跟踪标准 Open Tracing。国内,淘宝的“鹰眼”、京东的“Hydra”、大众点评的“CAT”、新浪的“Watchman”、唯品会的“Microscope”、窝窝网的“Tracing”都是这样的系统。
Spring Cloud Sleuth 介绍
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。虽然每一部分都可能变得很复杂,但基本原理都类似。
Spring Cloud Sleuth为服务之间调用提供链路追踪。Sleuth可以帮助我们:
- 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
- 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
Spring Cloud Sleuth的概念图:
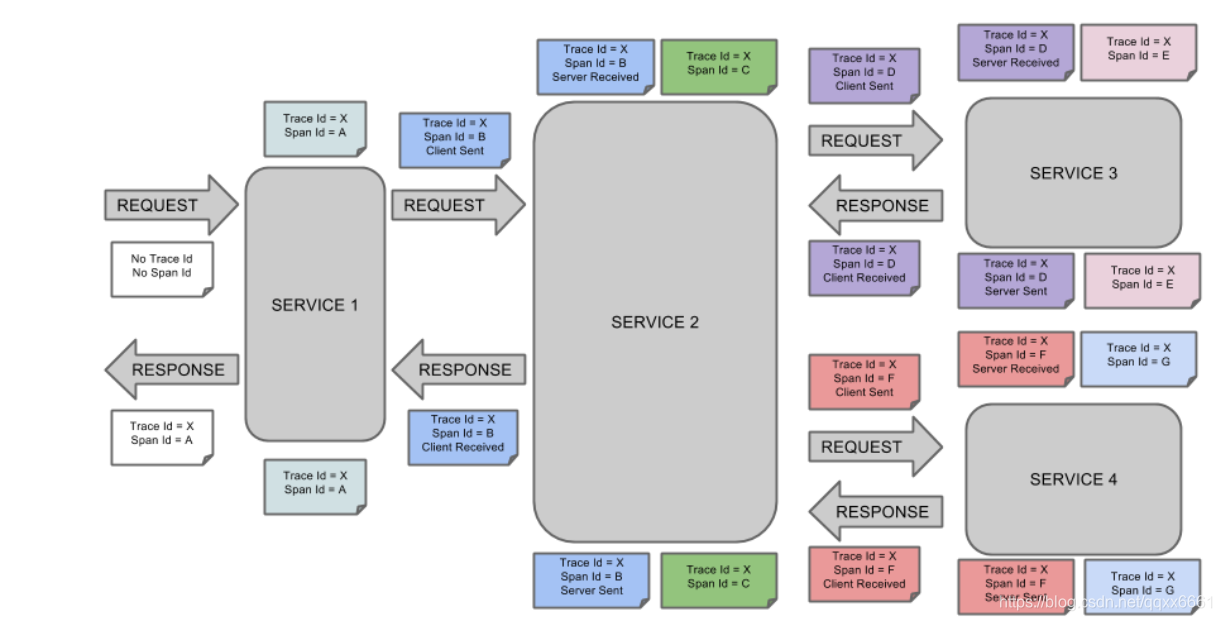
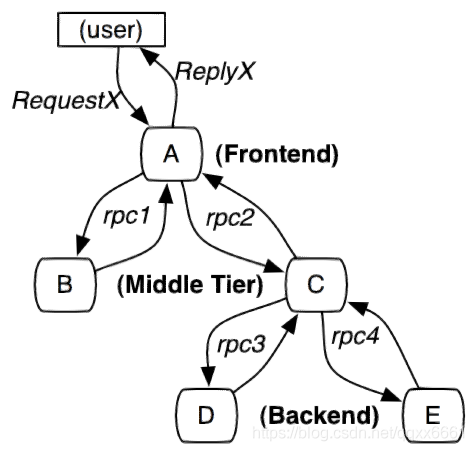
- trace:从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程.包含一系列的span,它们组成了一个树型结构
- span: 每个 trace中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。Span是基本的工作单元。Span包括一个64位的唯一ID,一个64位trace码,描述信息,时间戳事件,key-value 注解(tags),span处理者的ID(通常为IP)。
最开始的初始Span称为根span,此span中span id和 trace id值相同。 - Annotation: 用于及时记录存在的事件。常用的Annotation如下
- cs - Client Sent:客户端发送一个请求,表示span的开始
- sr - Server Received:服务端接收请求并开始处理它。(sr-cs)等于网络的延迟
- ss - Server Sent:服务端处理请求完成,开始返回结束给服务端。(ss-sr)表示服务端处理请求的时间
- cr - Client Received:客户端完成接受返回结果,此时span结束。(cr-sr)表示客户端接收服务端数据的时间
ZipKin介绍
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。
spring cloud sleuth结合zipkin
在使用 Spring Boot 2.x 版本后,官方就不推荐自行定制编译了,让我们直接使用编译好的 jar 包.也就是说原来通过@EnableZipkinServer或@EnableZipkinStreamServer的路子,启动SpringBootApplication自建Zipkin Server是不行了
安装和部署zipkin
官方提供了一键脚本
1 | curl -sSL https://zipkin.io/quickstart.sh | bash -s |
如果用 Docker 的话,直接
1 | docker run -d -p 9411:9411 openzipkin/zipkin |
我使用脚本的方法,在IDEA的terminal里运行java -jar zipkin.jar
访问 http://localhost:9411/zipkin/ :
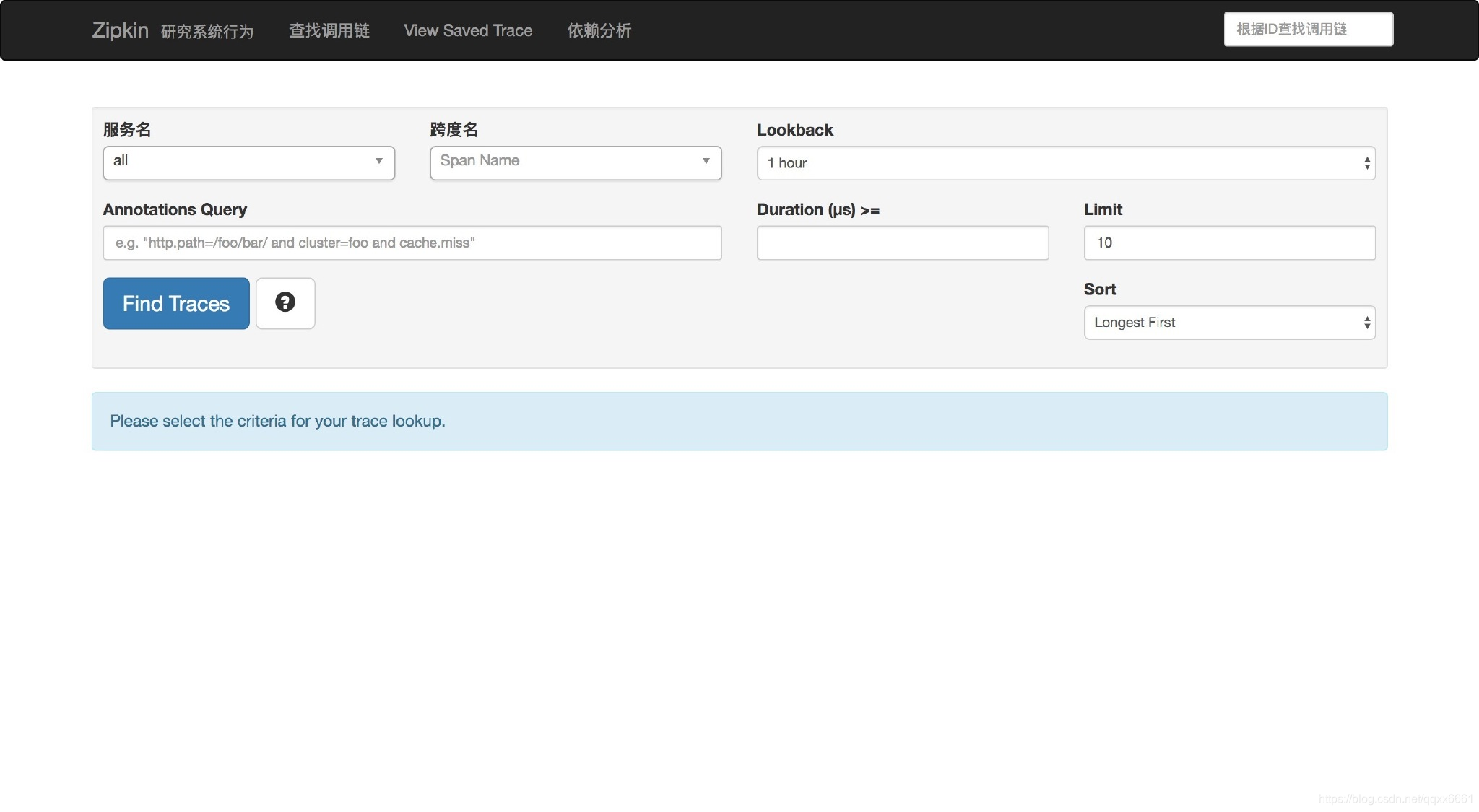
修改service-feign和eureka-hi模块设置
接下来我们需要建造一串调用,我们使用之前的模块service-feign和eureka-hi
修改子模块eureka-hi和service-feign的pom文件:
添加三个依赖:
1 | <!--分布式链路追踪--> |
修改子模块eureka-hi和service-feign的yml配置文件,添加相关配置:
1 | spring: |
Spring Cloud Sleuth 有一个 Sampler 策略,可以通过这个实现类来控制采样算法。采样器不会阻碍 span 相关 id 的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth 默认采样算法的实现是 Reservoir sampling,具体的实现类是 PercentageBasedSampler,默认的采样比例为: 0.1(即 10%)。不过我们可以通过spring.sleuth.sampler.percentage来设置,所设置的值介于 0.0 到 1.0 之间,1.0 则表示全部采集。
至此,一切就绪。Spring 应用在监测到 classpath 中有 Sleuth 和 Zipkin 后,会自动在 WebClient(或 RestTemplate)的调用过程中向 HTTP 请求注入追踪信息,并向 Zipkin Server 发送这些信息。
测试运行
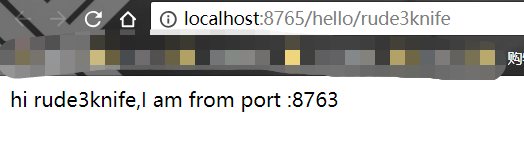
我们使用service-feign的接口来远程调用eureka-hi:
运行service-feign,eureka-hi,eureka,并且加上之前运行着的zipkin。
http://localhost:8765/hello/rude3knife
再打开 http://127.0.0.1:9411/zipkin/ :
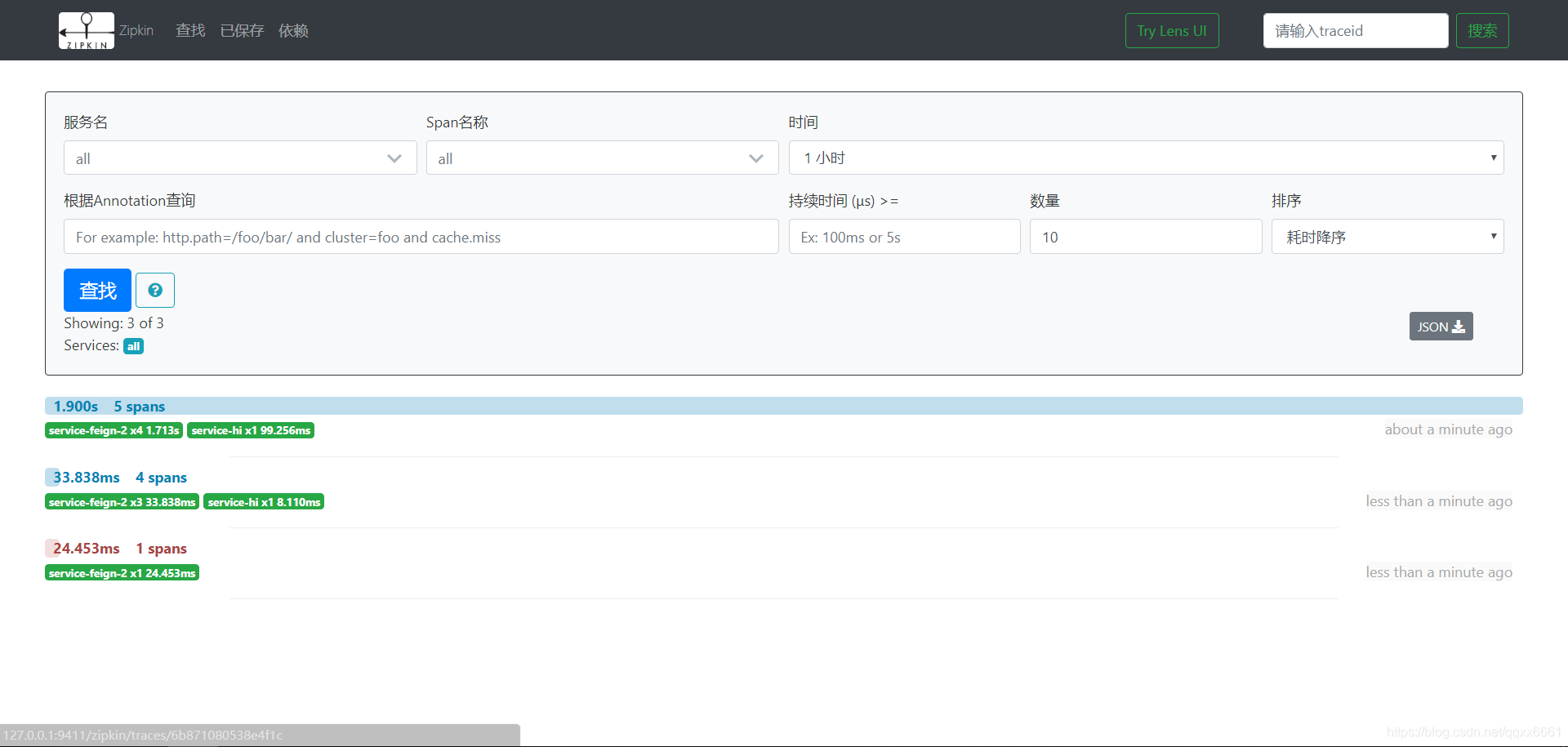
点击其中一个:
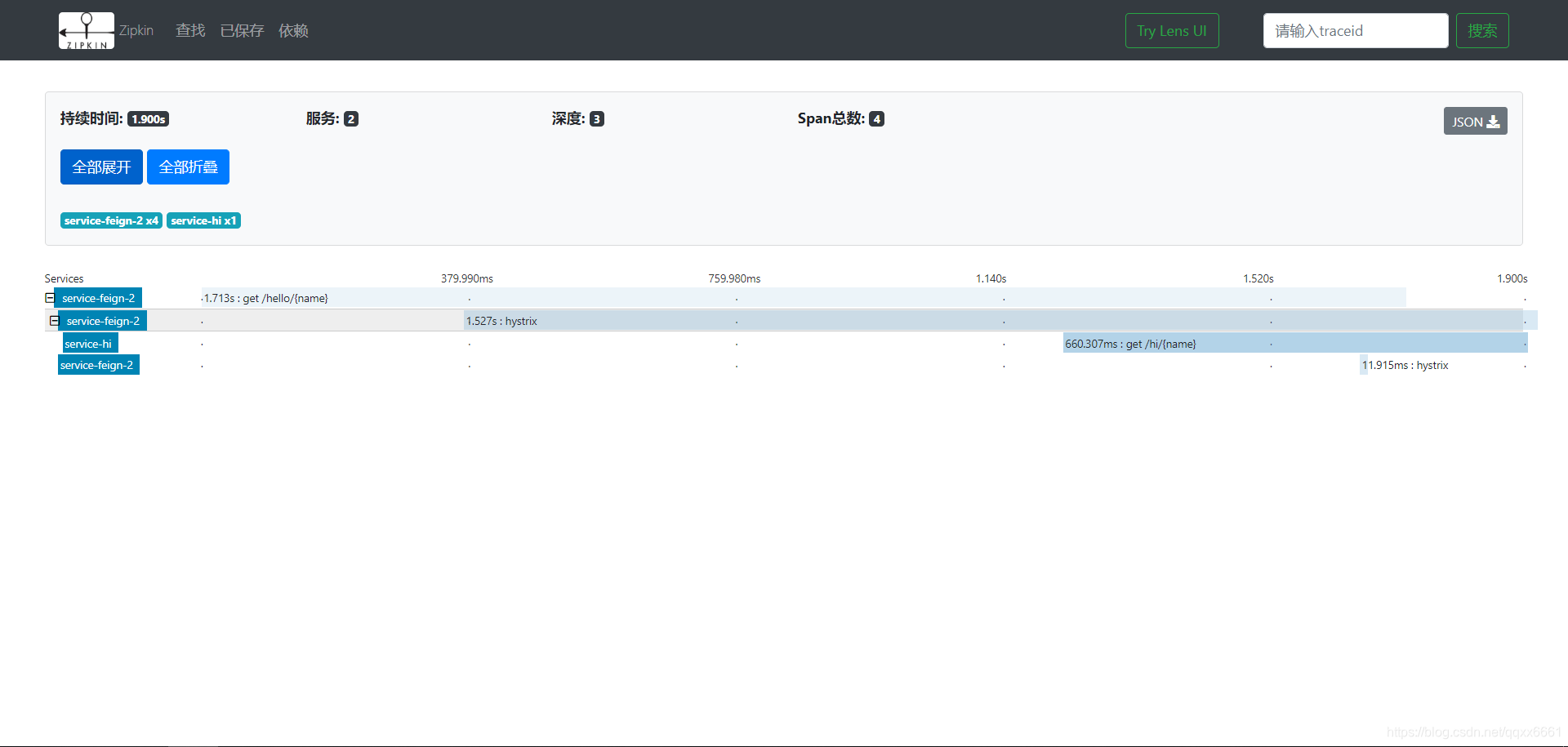
可以看到每一个服务所耗费的时间和顺序。
还可以点击左上方“依赖分析”,可以查看服务之间的调用关系:
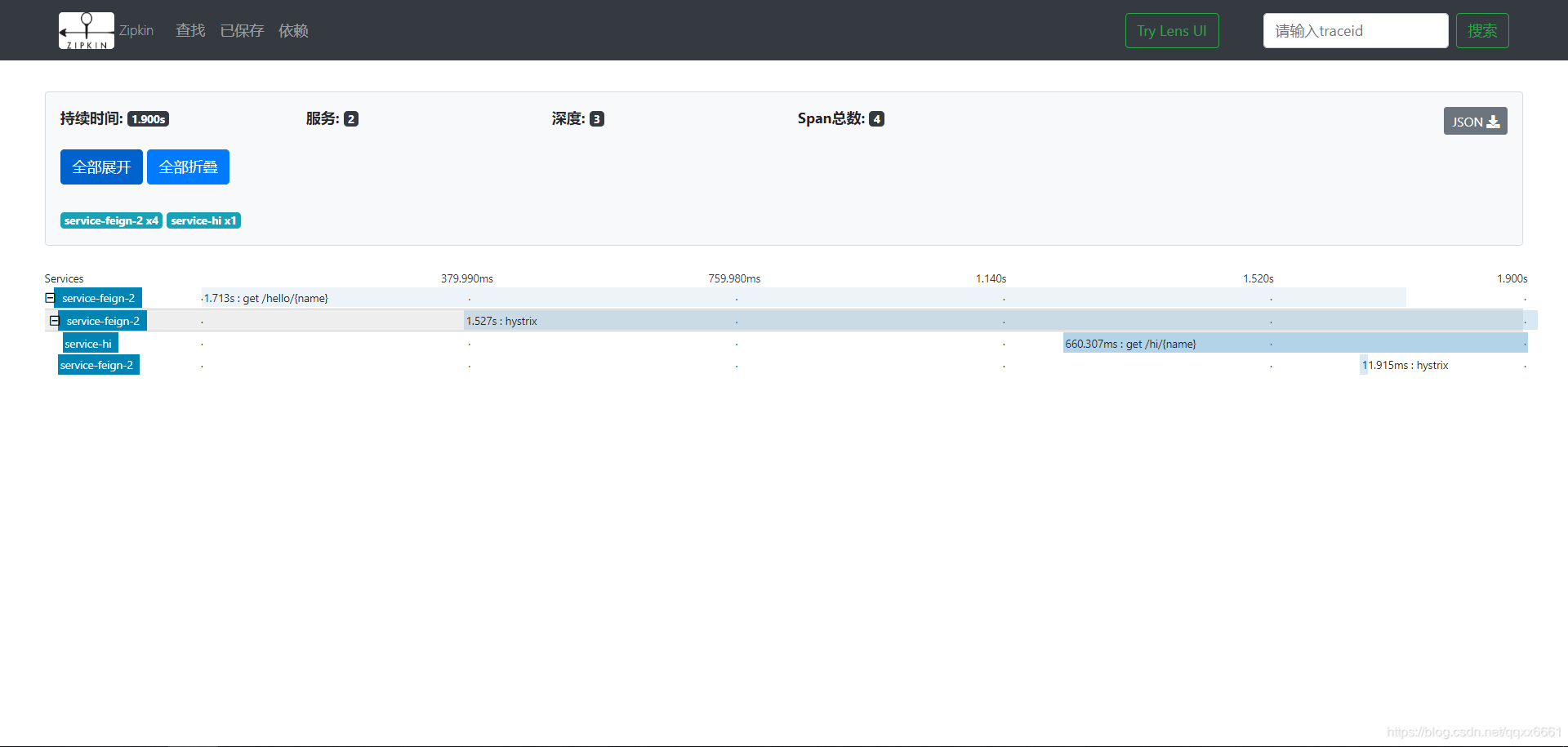
完成啦。
本章代码
https://github.com/qqxx6661/springcloud_for_noob/tree/master/10-spring-cloud-sleuth-zipkin
参考
http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html
https://blog.csdn.net/hry2015/article/details/78905489
https://www.cnblogs.com/softidea/p/7612570.html
https://windmt.com/2018/04/24/spring-cloud-12-sleuth-zipkin/
—–正文结束—–
菜鸟SpringCloud实战入门专栏全导航:通过以下两种途径查看
- 关注我的公众号:Rude3Knife 点击公众号下方:技术推文——SpringCloud
- 菜鸟SpringCloud实战专栏(CSDN)
关注我
我是蛮三刀把刀,后端开发。主要关注后端开发,数据安全,爬虫等方向。微信:yangzd1102
Github:@qqxx6661
个人博客:
原创博客主要内容
- Java知识点复习全手册
- Leetcode算法题解析
- 剑指offer算法题解析
- SpringCloud菜鸟入门实战系列
- SpringBoot菜鸟入门实战系列
- Python爬虫相关技术文章
- 后端开发相关技术文章
个人公众号:Rude3Knife
如果文章对你有帮助,不妨收藏起来并转发给您的朋友们~